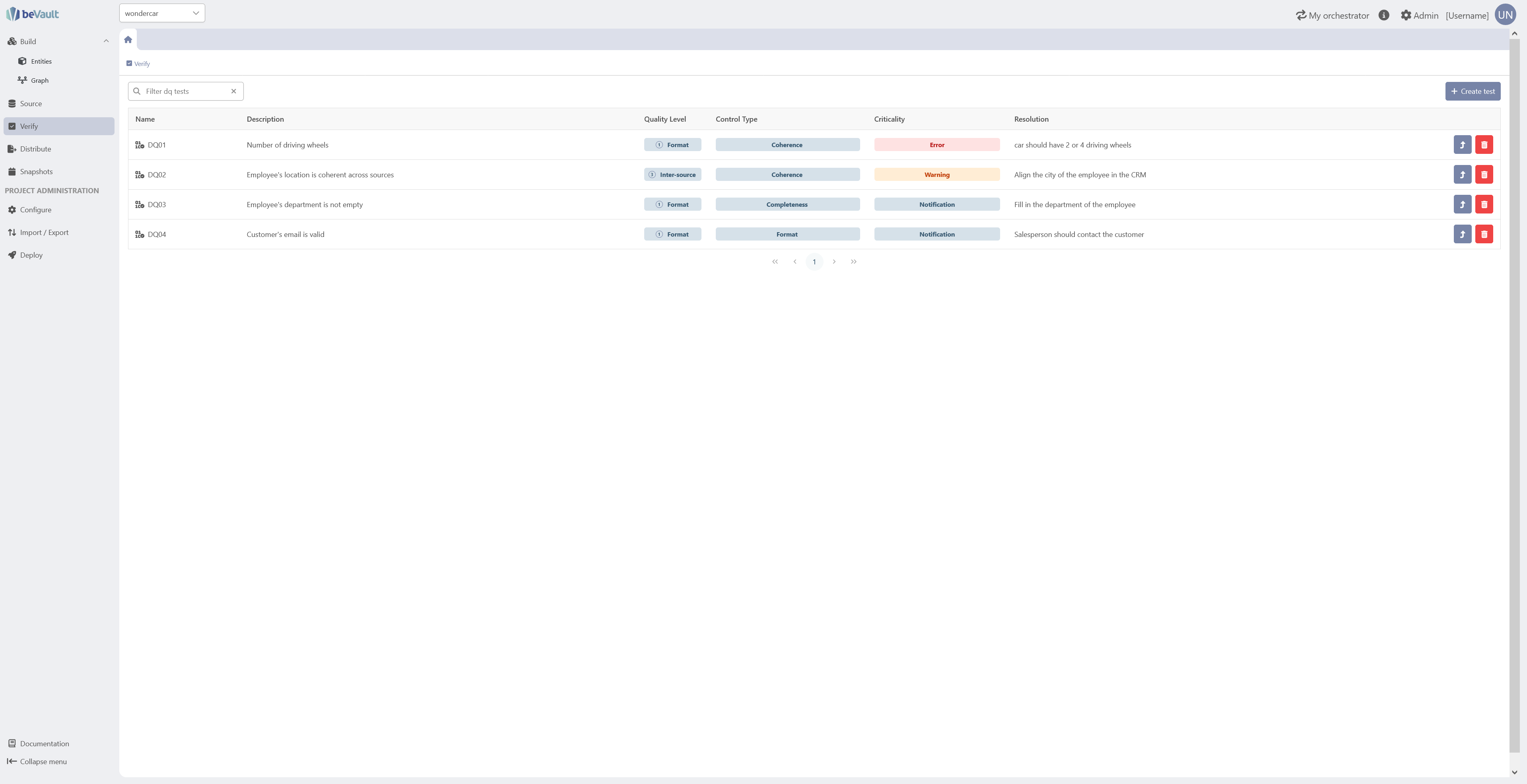
This submodule allows the users to manage their data quality test on the raw data. This way, the different owners of the data can have a clear view of their data quality issues.
In this section, we will describe the data quality framework of beVault, how to manage the data quality tests, and how the users can use their tests' results.
Data Quality Framework
The purpose of Data Quality is to dispose of an unambiguous metric about the quality of the data used to produce information.
It ensures that the data we receive is “good enough” to be displayed in reporting for decision-makers and also to feed multiple other systems.
Indeed, those decision-makers cannot infer any conclusions from data if they are not confident enough that these data reflect the truth about their business. Thus, they cannot take any decisions based on non-qualitative data.
QI (Quality Indicators)
The purpose of the quality indicators is to establish a list as exhaustive as possible of useful quality controls.
Every quality control should be thought of so that its result is a true or false, 1 or 0 value.
-
1 is that the control passes (OK);
-
0 is that the control fails (NOT OK).
To be able to do so, we first need to understand what are the different components and characteristics of quality control.
Components
Quality control has 3 main components:
-
Business Concept
-
Quality level
-
Source System
Business Concept
The key business concepts (projects, products, clients, suppliers, invoice, etc.) need to be checked in terms of quality across the different source systems.
In the case of beVault, it can be either a hub or a link.
Quality levels
The quality levels described the different aspects that will be checked into the database(s) to control the data quality.
There exist 4 levels that we are going to control.
The principle behind the quality levels is that each level has a granularity depending on the previous levels. The first level is the most important one, as if this points out quality issues, other levels will also have quality issues.
Furthermore, the levels are also implying a priority between them. There is no need to look at level 3 quality controls if levels 1 and 2 are not verified first.
Here are the quality levels :
|
Quality levels |
Data Quality Check Scope |
Data Quality Description |
|---|---|---|
|
Level 1 |
Form |
Checks the form of ONE parameter ex: isdate(X) |
|
Level 2 |
Intra-source |
Checks the quality between more than one parameter in one single source ex: value X < Value Y; if status = ‘validated’ then amounts should be >0 and a probability between 0 and 100% defined. |
|
Level 3 |
Inter-source |
Checks the quality between more than one parameter in more than one source ex: Value (source1.X) < Value (source2.Y) : owner of the project in accounting = owner of the project in project management tool. |
|
Level 4 |
Business plausibility |
All other checks, including the experience of analysts to check for the value of a record ex: Value(X) < 10^6
|
Level 1 = Form DQ Controls
The first level of quality controls aims to verify inside a particular source, across all the database records, if the required attributes of each key business concept exist and respect an appropriate format.
For instance, their purpose is to verify the format of a date or to verify the number of figures in a normalized identifier.
Examples:
-
has name (the field is not null);
-
has an ID (the field is not null);
-
has valid value (the values are either “true” or “false”),
-
has a valid name (the field always starts with a specific number or letter, the field contains a specific series of figures or letters, the field doesn’t contain specific terms such as “XXX” or “test”, etc.);
-
has a valid ID (the field always starts with a specific number or letter, the field contains a specific number of figures or letters, the field corresponds to a value of a specific referential, etc.).
Level 2 = Intra-Source DQ Controls
The second level of quality controls aims to verify inside a particular source, across all the database records, if the main attributes of each key business concept are consistent. This implies that a specific attribute needs to match some basic criteria to ensure consistency in the system.
For instance, ensure consistency based on a business referential or the sum of individual elements equals the total.
Examples:
-
has a consistent project date (the project end date should always be equal to or greater than the project start date).
Level 3 = Inter-Source DQ Controls
The third level of quality controls aims to verify across several sources if the main attributes of each key business concept are valid with each other. This implies that a specific attribute needs to match some basic criteria to ensure its validity between different sources in the system.
For instance, ensure consistency based on a business referential in another source or information entered in one source makes the link with complementary information in another source.
Examples:
-
has a valid name (the name should match the other names of the other sources);
-
has a valid ID (the ID should match with the other IDs of the other sources).
Level 4 = Business plausibility DQ Controls
The fourth level of quality controls that are not in the previous 3 categories but is relevant.
This may imply some business rules between attributes, where there exist some interdependencies between different sources that need to be verified to follow the business logic of the client. Some information may not be available directly in the sources but need to be provided as a business insight.
This presupposes that the previous levels (1, 2, and 3) present a sufficient quality.
For instance, an expected value is supposed to be between a range of another value from a different source or the sum of some amounts in one source shouldn’t be above a fixed value.
Examples:
-
has consistent project closing (if a project is closed in one system, it should be closed in others too).
Source System
A reference to the main source system where we get the data that needs to be used to feed the reporting solution of the client.
Characteristics
Quality control has several characteristics:
-
ID;
-
Name;
-
Description;
-
Controls Type;
-
Criticality;
-
Responsible;
-
Resolution.
ID
Every data quality control has the same structure: DQWXYZa
Where:
-
“DQ” is the prefix of every data quality control;
-
“W” corresponds to the main source system;
-
“X” corresponds to the business concept;
-
“Y” corresponds to the quality level;
-
“Z” corresponds to the number of the DQ control;
-
“a” if the number of the DQ controls exceeds 9, continue the numbering with alphabetical letters by restarting at 1 and adding the letter “a”.
Examples:
-
DQ1216;
-
DQ2211;
-
DQ3211.
Description
The description aims to give more details on the control performed (usually the affirmation that needs to be controlled).
Examples:
-
name <> ‘XXX’ and ‘test’;
-
client_id is required and unique;
-
ID format = C****.
Controls Type
When speaking about quality controls, there exist several types of controls.
-
Completeness: Does the data exist? This is an essential control to benefit from a precise overview of the completeness of the information provided. Without this, the data is not necessarily aligned with the expected scope.
-
Format: Is the data exploitable? This is a control making it possible to validate that the source system applies formatting, on input, adapted to the different fields. Without it, the data may have errors in the consolidation of information.
-
Freshness: Is the data up-to-date? This is a control making it possible to validate that the reality represented is well aligned with the temporality defined in the decision-making cycle. Without it, the data can represent heterogeneous temporalities.
-
Coherence: Is the data coherent? This is a “smart” control to validate that the data responds to certain business logic. Without it, the data may have misalignment or inconsistencies that are difficult to identify.
Criticality
To help quality responsible in their assessment of the quality issues they could face, each DQ control has a criticality level associated.
-
Error (high criticality): this is for DQ controls that highlight a system error and an integrity issue. Those errors require immediate and corrective action because they imply a non-interpretation of the data. It considers “essential” elements to the realization of the reporting and to the primary reading of the decision tables. High criticality helps prevent “blind spots” related to the lack of information to link the data to the display structure.
-
Ex: A value linked to a benchmark that serves as a filter for the reporting. An indicator is necessary for decision-making.
-
-
Warning (medium criticality): this is for DQ controls that highlight conformity issues. Those warnings need to be corrected as soon as possible to avoid misinterpretation and bias in the data that couldn’t tell a single version of the truth. It considers “support” elements for decision-making and understanding of the data. They provide context to the essential elements. Without them, contextualization is defective.
-
Ex: An indicator whose data provides context or perspective only.
-
-
Notification (low criticality): this is for DQ controls that highlight minor data quality issues. Those notifications are used as information that needs to be analyzed to provide some improvement actions in the source system. It considers “complementary” elements which are not essential to the performance of reporting (filters, etc.) and which do not impact the decision tables.
-
Ex: A comment field that describes the successes if those are not necessary for decisions.
-
Responsible
Our methodology aims to focus on continuous improvement and supports the theory that data quality is a journey, not a destination. To ensure that this journey is maintained, the responsibility of its execution needs to be clearly identified.
That is why we advocate defining responsible (project managers, account managers, etc.) that will be informed of the quality level of their area to take the necessary actions to keep it as high as possible.
Resolution
Once the quality issues are highlighted and the responsible identified, the next step is to resolve those issues to ensure they won’t happen again. To do so, every quality control has a resolution that aims to tell the responsible what he needs to do to resolve the quality issue.
Create a data quality test
To create a data quality test, click on the “Create Test” button. This will open a form that requires you to provide some required and additional attributes, divided into four steps.
Descriptive information
This first step contains all the descriptive information of the data quality test. That information is displayed in the list of DQ tests.
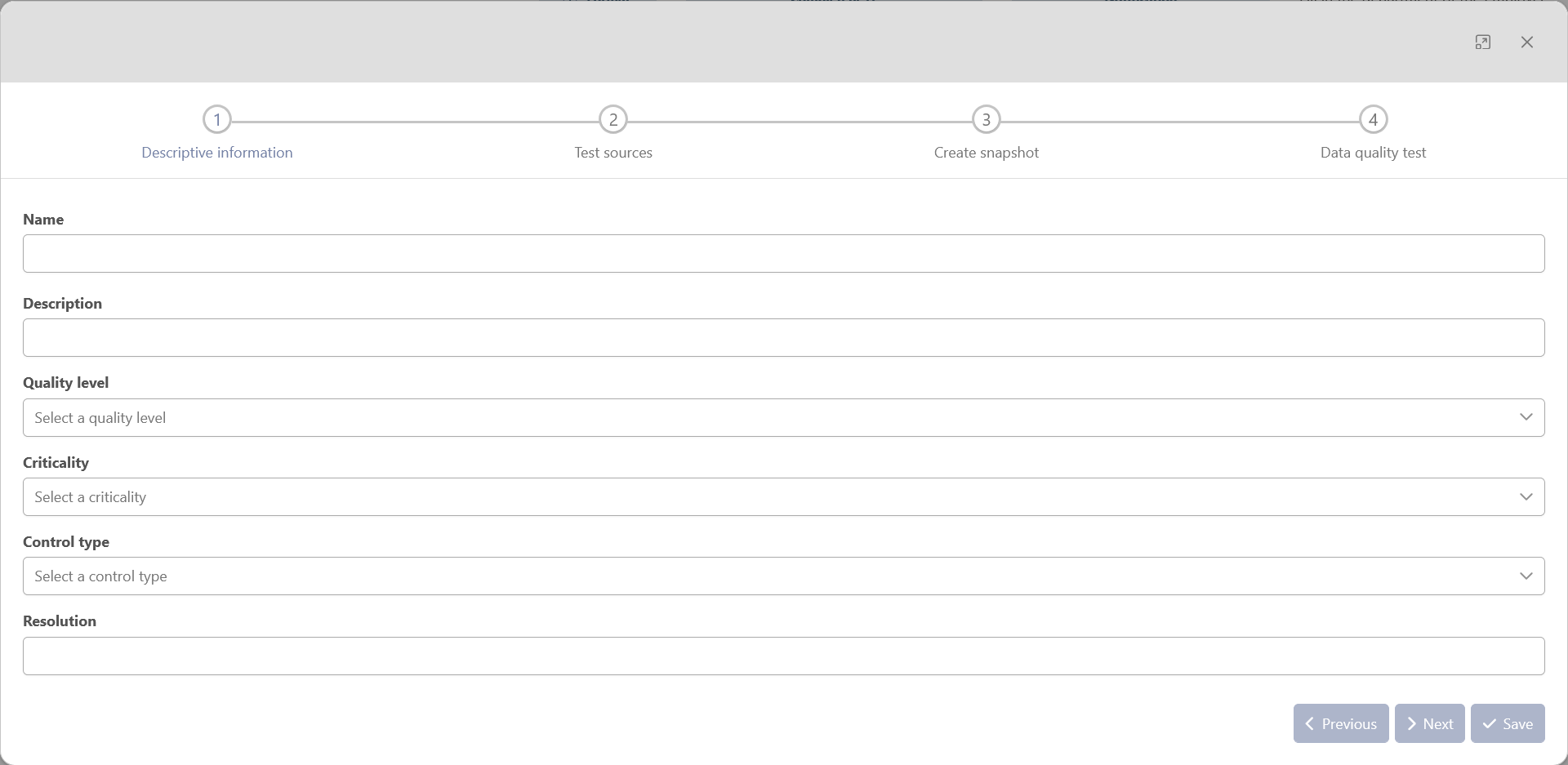
-
Name: mandatory — the name of the data quality test. (CFR ID in Data Quality Framework) The name must be at least 2 characters and no more than 25 characters long. It must start with a letter or underscore, and can be followed by letters, digits, and underscores.
-
Description: optional — provide a description of the data quality test.
-
Quality Level: mandatory — select a quality level from 1 to 4. (CFR Data Quality Framework)
-
1 — Form
-
2 — Intra-source
-
3 — Inter-source
-
4 — Business plausibility
-
-
Criticality: mandatory — to help quality responsible assess the potential risk of the quality issues. (CFR Data Quality Framework)
-
Notification
-
Warning
-
Error
-
-
Control type: mandatory — the type of check that is performed on the data. (CFR Data Quality Framework)
-
Completeness
-
Format
-
Freshness
-
Coherence
-
-
Resolution: mandatory — a message for the person in charge of the data to help him resolve or understand the issue
Test Sources
This second step contains the information to locate the issue (source, responsible, point in time, …)
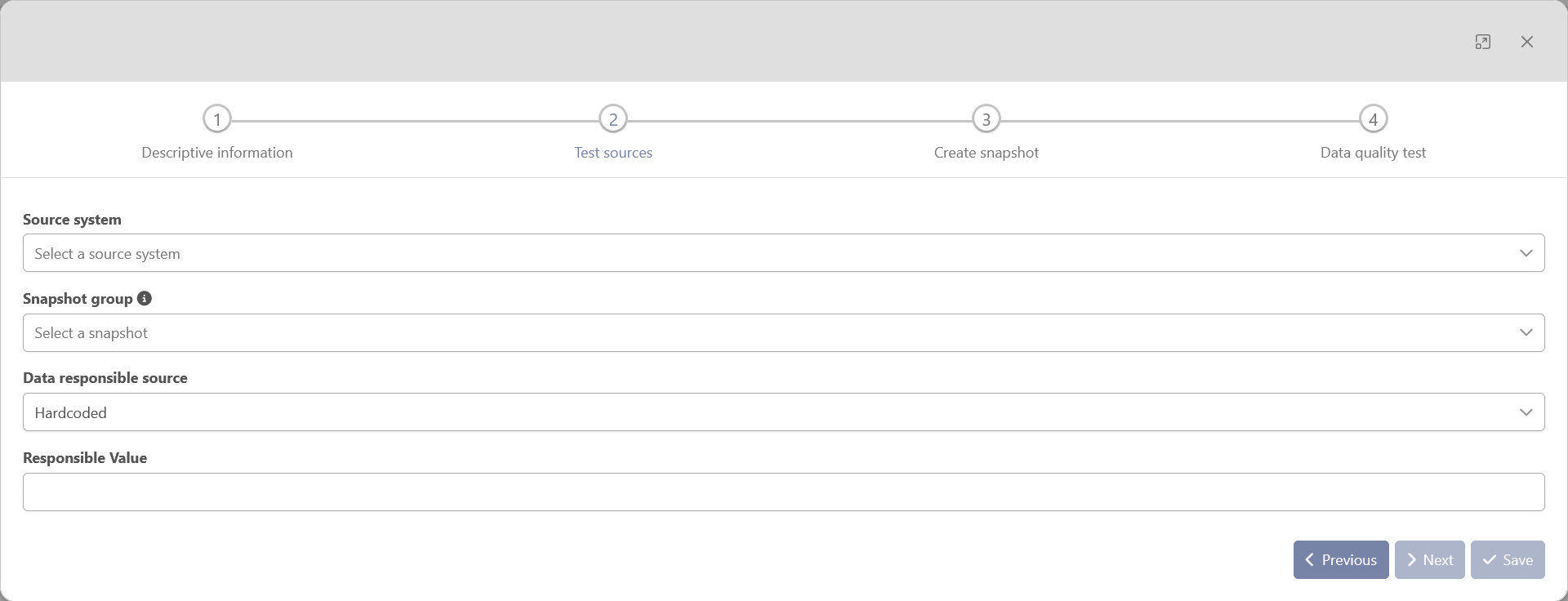
-
Source System: mandatory — The source system that contains the data that is being tested. If the data is coming from multiple source systems (e.g., a plausibility check to compare amounts between two systems), select the source that needs to be corrected.
-
Select Snapshot: mandatory — select the snapshot to be used. If a snapshot does not yet exist, you will be directed to the next step, “Create Snapshot.”.
-
Data Responsible: mandatory — defines who will be responsible for this data quality test, 3 options are currently available:
-
Hard-coded: a new text field “Responsible Value” will appear below where the users can encode a fixed value for all the results
-
Source System: the responsible will be the same as described in the Source System (CFR Source System submodule)
-
Query: a new dropdown list “IM Query” will appear below, requiring to select an existing query (CFR Information Mart submodule) that gives a person in charge of each tested value.
The query must contain two columns :-
HK : the hash key of the hub or the link that is being tested
-
name : the name of the person in charge of the tested object
-
-
Create snapshot
The third step of the creation of the data quality tests is optional. This step is accessible if the user didn’t select an existing snapshot.
More information regarding the snapshot creation can be found in the documentation of the snapshot submodule.
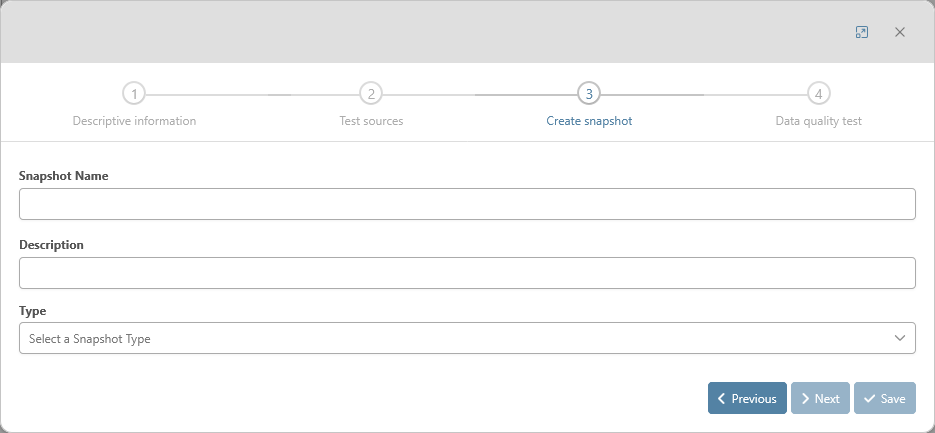
Data quality test
The last step is the creation of the test itself. This information will be used to execute the test afterward.
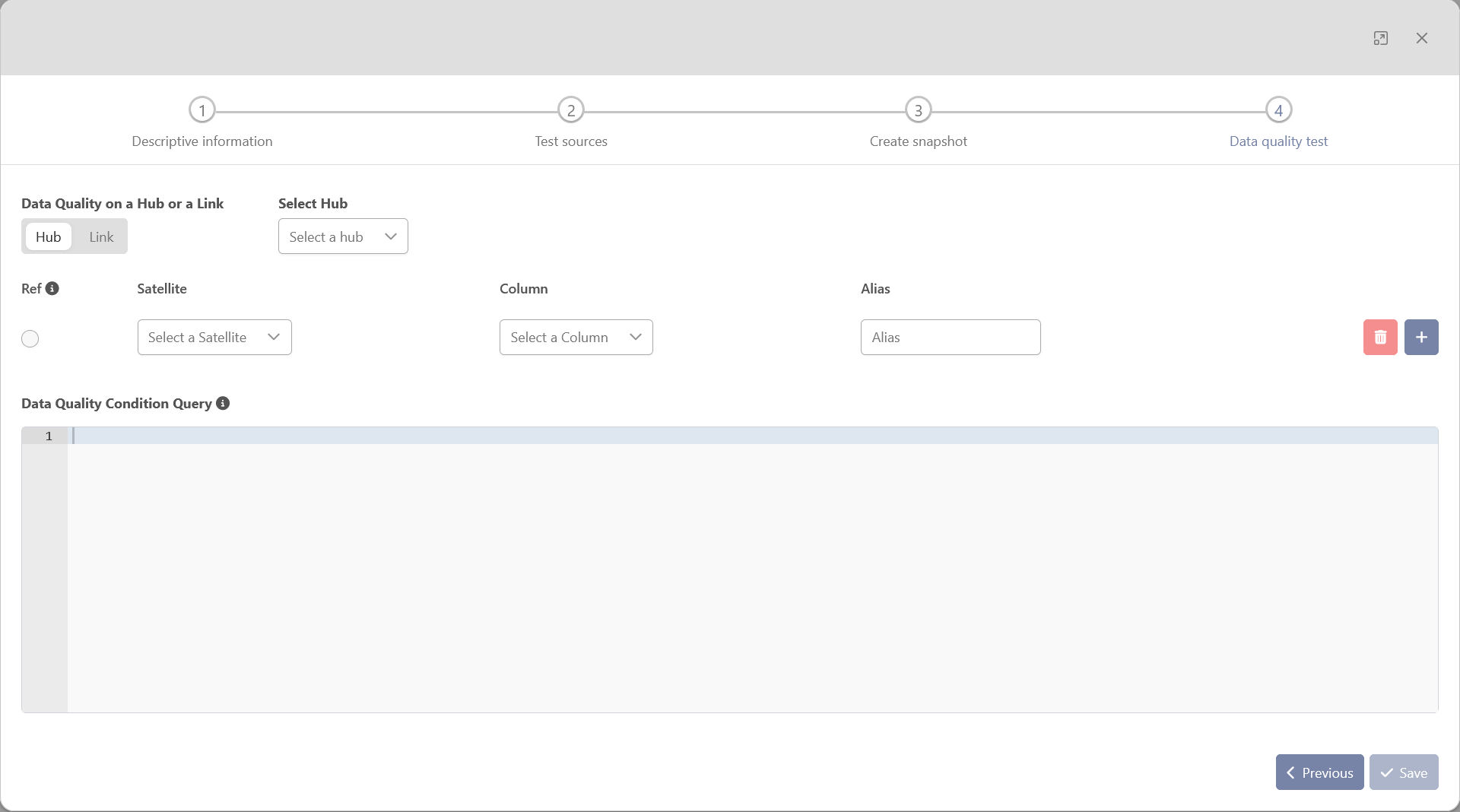
-
Data Quality on a Hub or a Link: mandatory — select either a Hub or a Link, the entity that will be tested.
-
Select Hub (or Link): mandatory — selection of the related hub or link.
-
Parameters mandatory — One or more parameters that will be used for the test
-
Ref: mandatory — Select one of those columns to use it as descriptive data of the tested object.
-
Satellite: mandatory — the satellite on which data quality test query will be applied.
-
Column: mandatory — The satellite’s columns on which data quality test query will be applied.
-
Alias: optional — option to help the user if he wants to use fields with long names and avoid typing it. If the field is not specified, the default alias will be the same as the column name.
-
-
Data Quality Condition Query: mandatory — The SQL condition for the test to pass. The script should be written in SQL and be compatible with the type of database of the environments of the project.
Please know that no data quality control can be created on the fields of the multi-active satellites through this feature
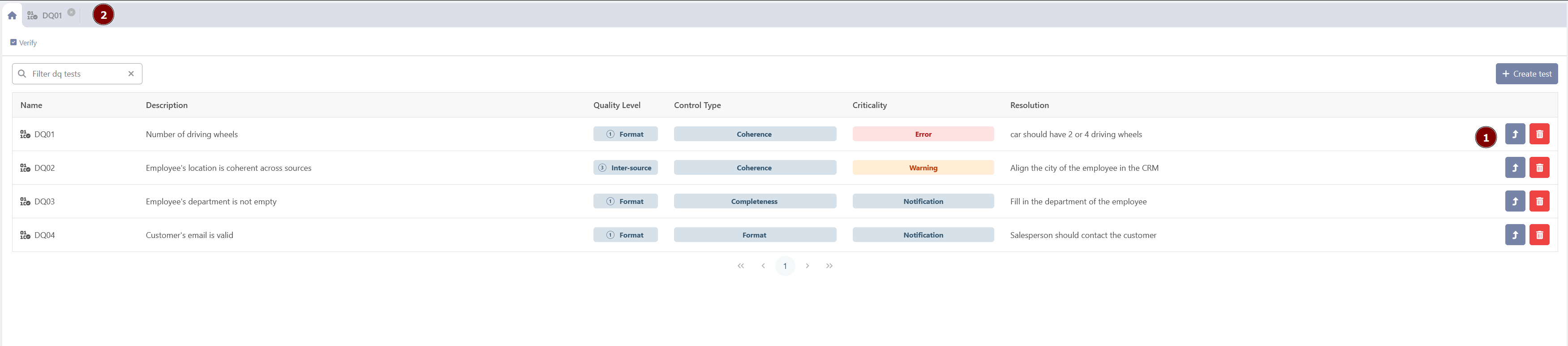
Update a data quality test
To update the information about a data quality tests, the users can open a dynamic tab with the dedicated edit button (1).
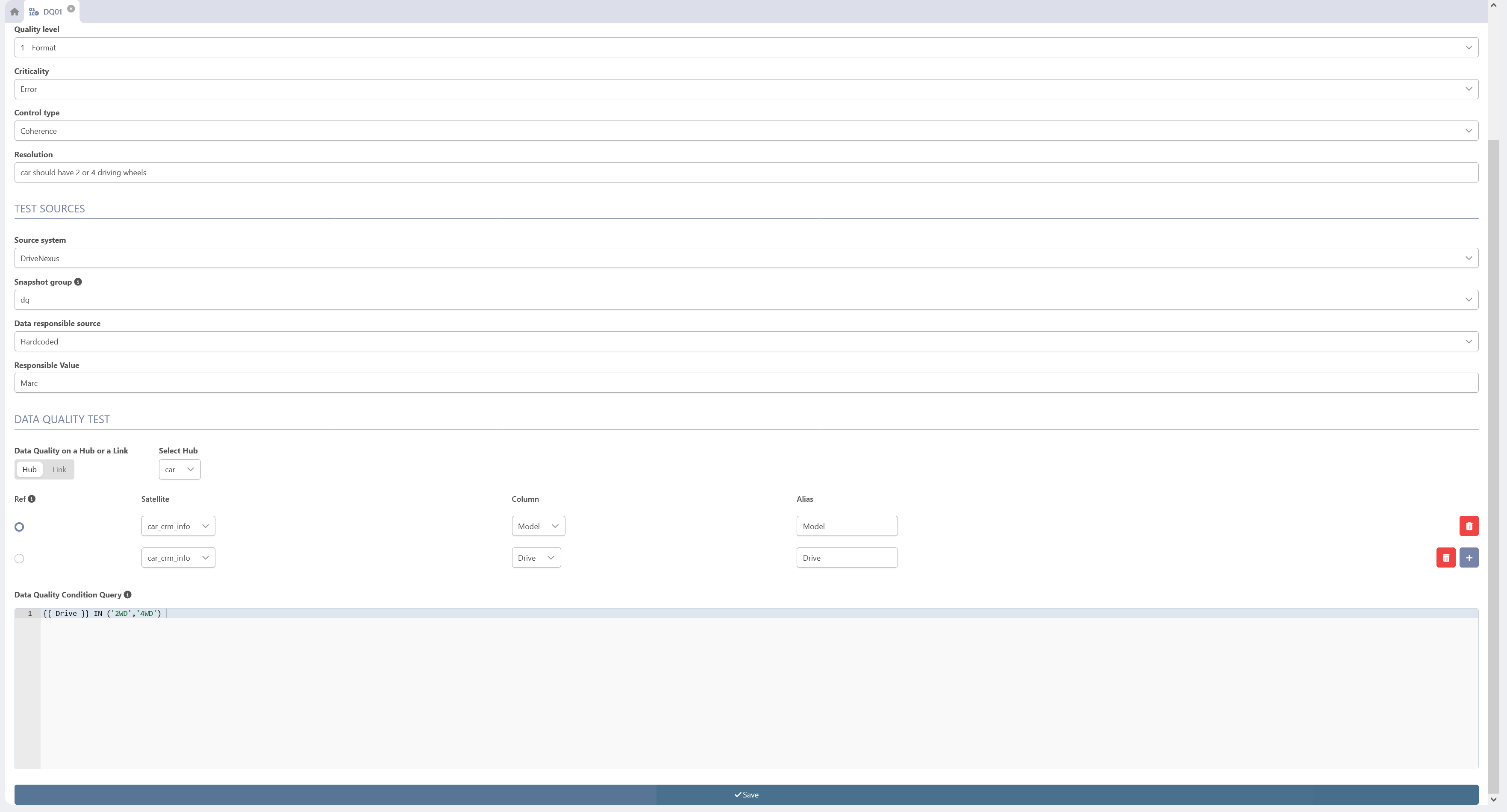
Once the dynamic tab is open, the descriptive information can be edited and saved with the button “save” at the bottom of the tab.
Delete a data quality test
The users can delete the data quality test with the trash can button.

Output
Once created and deployed, the data quality test will be integrated into the state machine of the snapshot. The test will be performed for each snapshot date of the DQ test, with the execution of the generated state machine.
The results and the list of data quality tests can be found in two views in the Information Mart schema (im) : im.dim_dq_controls and im.fact_dq_results
im.dim_dq_controls
This auto-generated table contains the list of all the data quality tests deployed on this environment.

-
dq_id : autogenerated-id of the DQ test. Used to link it to im.fact_dq_results
-
name: name of the DQ test
-
description: description of the test
-
principal_source: source selected during the creation of the DQ test
-
business_concept: hub or link name of the DQ test
-
quality_level: number of the quality level
-
quality_level_description: name of the quality level
-
controls_type: type of the control
-
criticality: criticality of the DQ issue
-
resolution: resolution to fix the DQ issue
-
expression: SQL condition executed for the test
im.fact_dq_results

-
dq_id : autogenerated-id of the DQ test. Used to link it to im.dim_dq_controls
-
object_id: business key of the hub (or concatenation of the business keys of the link’s hub references) on which the test has been executed
-
responsible: responsible for this DQ test
-
result: result of the DQ test. 1 for the test that passed, 0 for the one that failed
-
denom: 1
-
date: snapshot_date for which the result is valid
-
object_name: value of the column flagged as Ref (CFR creation of DQ test)
-
entity_hk: hash key of the hub or link on which the test is performed