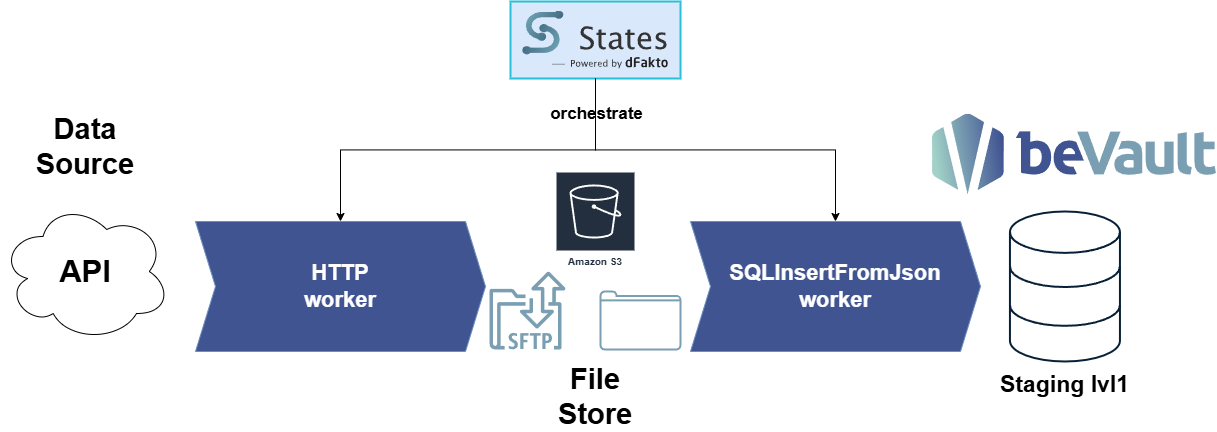
This guide shows three common patterns to extract data from a REST API using the Http worker, persist the response to a fileStore (e.g., S3), and load it into a staging layer:
-
Pattern A: Simple extraction to fileStore, then direct column mapping into a staging table (with truncate first).
-
Pattern B: Dump raw JSON into a “single-column” staging table and pivot via a staging view.
-
Pattern C: Handle paginated APIs (loop over pages using Link headers).
Sending API responses to a fileStore avoids overloading State logs and prevents data from being written to execution logs.
Prerequisites
-
The fileStore “extract” (or your chosen store) is configured and accessible by the Http and sqlInsertFromJson workers.
-
Staging database connection(s) exist (e.g., bevault-staging).
=> CFR https://dfakto.atlassian.net/wiki/x/AoDCjgE to see how to configure the different stores required
-
API credentials are available (often injected via HttpHeaders Authorization or similar).
-
Target staging tables exist (or you have DDL ready to create them).
Pattern A — Direct column mapping into a staging table
Goal:
-
Truncate the staging table at the start.
-
Call the API with the Http worker, streaming the response to fileStore.
-
Load selected fields into a staging table with sqlInsertFromJson.
This pattern keeps logs clean and maps only the columns you need.
State machine
Assumptions:
-
JiraParameters is present in state input (e.g., passed in or loaded earlier). If not, add an initial SQLQuery Reader step to fetch parameters from a ref table.
{
"StartAt": "truncate_staging_table",
"States": {
"truncate_staging_table": {
"Type": "Task",
"Resource": "Production-SQLQuery",
"ResultPath": "$.TruncateResult",
"Parameters": {
"ConnectionName": "bevault-staging",
"Query": "TRUNCATE TABLE stg.jira_cloud_users",
"Type": "NonQuery"
},
"Next": "extract_data"
},
"extract_data": {
"Type": "Task",
"Resource": "Production-Http",
"ResultPath": "$.jira_users",
"Parameters": {
"OutputFileStoreName": "extract",
"OutputFileName": "jira-cloud/users.json",
"Uri.$": "States.Format('{}/users/search?maxResults=500', $.JiraParameters.result[0].base_rest_api_url)",
"HttpHeaders": {
"Authorization.$": "$.JiraParameters.result[0].authorization_header",
"X-Force-Accept-Language": "true",
"X-Language": "en"
},
"HttpQueryParams": {}
},
"Next": "insert_in_staging"
},
"insert_in_staging": {
"Type": "Task",
"Resource": "Production-sqlInsertFromJson",
"ResultPath": "$.is_loaded",
"Parameters": {
"ConnectionName": "bevault-staging",
"Schemaname": "stg",
"TableName": "jira_cloud_users",
"FileToken.$": "$.jira_users.contentFileToken",
"Columns": {
"url": "self",
"technical_id": "accountId",
"type": "accountType",
"display_name": "displayName",
"active": "active"
}
},
"End": true
}
}
Notes:
-
The Http worker writes the response to fileStore and only returns a metadata envelope (including contentFileToken). This keeps logs small and avoids exposing payloads in execution logs.
Pattern B — Dump raw JSON to a single-column staging table, then pivot in a view
Use this when the API returns complex, nested JSON and your mapping will evolve. You:
-
Truncate the dump table.
-
Extract and write the API response to fileStore.
-
Load the entire JSON into a single text/JSON column.
-
Create a staging view to pivot/explode arrays and expose typed columns.
State machine
{
"StartAt": "truncate_dump",
"States": {
"truncate_dump": {
"Type": "Task",
"Resource": "Production-SQLQuery",
"Parameters": {
"ConnectionName": "bevault-staging",
"Query": "TRUNCATE TABLE stg.users_dump",
"Type": "NonQuery"
},
"ResultPath": "$.truncateResult",
"Next": "get_data"
},
"get_data": {
"Type": "Task",
"Resource": "Production-Http",
"Parameters": {
"Method": "GET",
"Uri.$": "States.Format('https://{}/api/users',$.baseUri)",
"HttpHeaders": {
"Authorization.$": "States.Format('Bearer {}', $.tokenResult.jsonContent.access_token)"
},
"outputFileName": "extract_api/users.json",
"outputFileStoreName": "extract"
},
"ResultPath": "$.usersResult",
"Next": "insert_data"
},
"insert_data": {
"Type": "Task",
"Resource": "Production-sqlInsertFromJson",
"Parameters": {
"connectionName": "bevault-staging",
"Schemaname": "stg",
"TableName": "users_dump",
"FileToken.$": "$.usersResult.contentFileToken",
"columns": {
"output": "$"
}
},
"ResultPath": "$.is_loaded",
"End": true
}
}
}
Staging table DDL
CREATE TABLE IF NOT EXISTS stg.users_dump (
output text
);
Example staging view to pivot the JSON
The example below:
-
Reads the API’s Records array from the stored JSON.
-
Exposes selected fields as columns.
-
Leaves nested ExternalIdentifiers as raw text (you can further normalize it if needed).
CREATE OR REPLACE VIEW stg.v_users AS
SELECT
rec ->> 'Id' AS person_unique_id,
rec ->> 'GivenName' AS first_name,
rec ->> 'FamilyName' AS last_name,
rec -> 'Email' ->> 'Address' AS email_address,
(rec -> 'ExternalIdentifiers')::text AS external_ids_raw
FROM stgusers_dump d
CROSS JOIN LATERAL jsonb_array_elements(
COALESCE(d.output::jsonb -> 'Records', '[]'::jsonb)
) AS rec;
Tips:
-
As API shapes evolve, you only update the view logic—your ingestion remains unchanged.
-
For deeply nested objects and arrays, combine jsonb_array_elements, jsonb_to_recordset, and additional lateral joins.
-
In this example, the mappings between the staging and the raw vault are done on the view. There will be no mapping on the staging table stg.users_dump.
-
You can create as many views as needed on the dump table to create specific staging view in case of multiple nested objects in the JSON.
Pattern C — Extract from a paginated API (example: Shopify with Link headers)
This pattern:
-
Loads API parameters from a reference table.
-
Truncates the dump table.
-
Fetches the first page to fileStore and loads it.
-
If a Link header contains rel="next", it extracts the next URL and loops until exhaustion.
State machine
{
"StartAt": "api_parameters",
"States": {
"api_parameters": {
"Type": "Task",
"Resource": "Production-SQLQuery",
"ResultPath": "$.ShopifyParameters",
"Parameters": {
"ConnectionName": "bevault-staging",
"Query": "SELECT * FROM ref.shopify_parameters",
"Type": "Reader"
},
"Next": "truncate_customers_table"
},
"truncate_customers_table": {
"Type": "Task",
"Resource": "Production-SQLQuery",
"ResultPath": "$.TruncateResult",
"Parameters": {
"ConnectionName": "bevault-staging",
"Query": "TRUNCATE TABLE stg.shopify_customer_dump",
"Type": "NonQuery"
},
"Next": "extract_customers"
},
"extract_customers": {
"Type": "Task",
"Resource": "Production-Http",
"ResultPath": "$.customers",
"Parameters": {
"OutputFileStoreName": "extract",
"OutputFileName": "shopify/customers.json",
"Uri.$": "States.Format('{}customers.json?limit=10', $.ShopifyParameters.result[0].base_rest_api_url)",
"HttpHeaders": {
"X-Shopify-Access-Token.$": "$.ShopifyParameters.result[0].authorization_header"
},
"HttpQueryParams": {}
},
"Next": "load_customers"
},
"load_customers": {
"Type": "Task",
"Resource": "Production-sqlInsertFromJson",
"ResultPath": "$.is_loaded",
"Parameters": {
"ConnectionName": "bevault-staging",
"Schemaname": "stg",
"TableName": "shopify_customer_dump",
"FileToken.$": "$.customers.contentFileToken",
"Columns": {
"customers": "customers"
}
},
"Next": "has_links"
},
"has_links": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.customers.httpHeaders.Link",
"IsPresent": true,
"Next": "read-link"
}
],
"Default": "done"
},
"read-link": {
"Type": "Task",
"Resource": "Production-SQLQuery",
"ResultPath": "$.link",
"Comment": "Extract the next-page URL from the Link header (rel=\"next\").",
"Parameters": {
"ConnectionName": "bevault-staging",
"Query.$": "States.Format('SELECT substring(split_part(link, '';'', 1), ''<(.*)>'') AS link FROM UNNEST(STRING_TO_ARRAY(''{}'', '','')) link WHERE substring(split_part(link, '';'', 2), '' rel=\"(.*)\"'') = ''next''', $.customers.httpHeaders.Link[0])",
"Type": "Reader"
},
"Next": "extract_more_choice"
},
"extract_more_choice": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.link.result[0].link",
"IsPresent": true,
"Next": "extract_more"
}
],
"Default": "done"
},
"extract_more": {
"Type": "Task",
"Resource": "Production-Http",
"ResultPath": "$.customers",
"Parameters": {
"OutputFileStoreName": "extract",
"OutputFileName": "shopify/customers.json",
"Uri.$": "$.link.result[0].link",
"HttpHeaders": {
"X-Shopify-Access-Token.$": "$.ShopifyParameters.result[0].authorization_header"
},
"HttpQueryParams": {}
},
"Next": "load_customers"
},
"done": {
"Type": "Pass",
"End": true
}
}
}
Good practices and notes
-
Keep payloads out of logs: Always use OutputFileStoreName/OutputFileName (or their lowercase variants) so the Http worker writes to fileStore. Downstream steps should pass around contentFileToken rather than the JSON body.
-
Idempotency: Truncate at the beginning of the flow when you are doing full refreshes.
-
Parameterization: Drive URIs, headers, and connection names from reference tables or State input to make flows reusable across projects/environments.
-
Pagination variants: Some APIs paginate with numeric page/offset or cursor parameters instead of Link headers. Adapt the loop to increment the page or pass the cursor returned by the previous call.
-
Rate limiting and retries: If your API enforces limits, configure retry policies on the Http task (backoff, max attempts) and consider pause/sleep steps between requests.
-
Schema drift: Prefer Pattern B for rapidly changing or deeply nested JSON. Use views to stabilize downstream consumption.