beVault 3.0 - Impact and migration
With version 3.0, beVault becomes the first tool to be certified by the Data Vault Alliance.
This means that all the tables generated in the database follow strictly the Data Vault 2.0 standard. To achieve this certification, we had to change some generated tables and concepts.

Upgrading from version 2.1 to 3.0 has some impacts on the tables that are generated and therefore, a migration should be done. We tried to limit the impact as much as possible to avoid a heavy migration process, but depending on your implementation of beVault, you might still have some minor manual action to perform to upgrade your project.
This guide will assess if a manual migration is required for your beVault and list all the impacts on an existing data model.
List of changes
Ghost records
Ghost records are used to reference an empty or unknown record. This allows you to use an INNER JOIN which is more performant when querying objects.
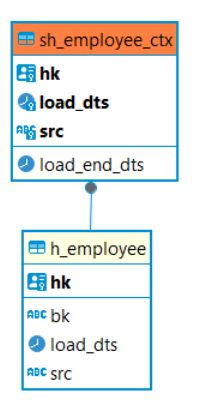
Historically, beVault had only one ghost record per entity :

ghost record before 3.0
To stick to the Data Vault 2.0 standard, we introduced 3 standards ghost records per entity where:
0 represents the concept itself (the hub or link). This ghost record is used in the pit tables but not in the raw vault
-1 represents a NULL business key that is normally required. It is used for the hub references in a link, for instance.
-2 represents a NULL business key that is optional. It is used for the hub references in a link, for instance.

ghost records in 3.0
Migration of ghost records
The migration process replaced the old ghost record by the 3 new ones. Here is the list of changes for each use case of the ghost records:
Deletion of the old ghost record (00000000-0000-0000-0000-000000000000 : NULL) from all entities
Insertion of the 3 new ghost records (0, -1, -2) in all entities
In the links
when the hub reference was 00000000-0000-0000-0000-000000000000, it has been replaced by the hash key of the ghost record -2 (5d7b9adc-be1c-629e-c722-529dd12e5129)
The hash key of the record is recomputed to match the new ghost record.
The hash key in the attached satellites for those records has been recomputed as well.
This change of ghost records might have an impact in your information marts if you used to filter on the NULL business key or its hash key.
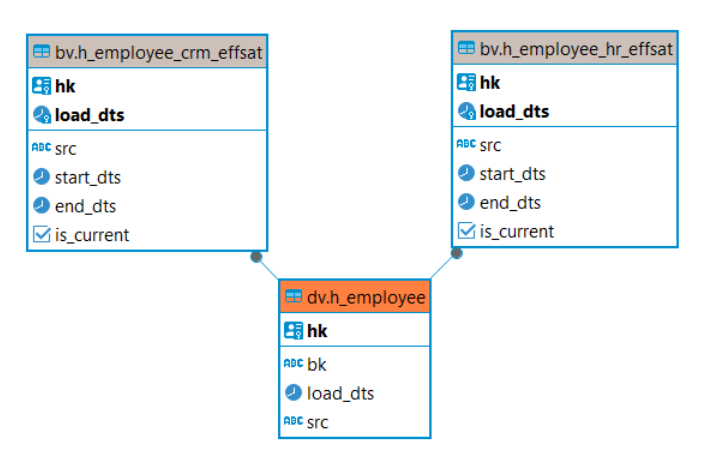
Context satellite → effectivity satellites
To track the effectiveness of a hub or link across time and source, we used to create and use context satellites. Those satellites didn’t follow the separation per source required for satellite, as we tracked the effectivity across sources in the same context satellite.
As of version 3.0, effectivity satellites have replaced the context satellite. Those satellites have the same purpose but follow the Data Vault 2.0 standard.
The structure of the table is essentially the same, but here are the differences:
one effectivity satellite per source
they are created in the business vault (bv schema) instead of the raw vault (dv schema)
they have a column ‘is_current’ that tracks the currently effective records
context satellite in v2.1
Effectivity satellites in v3.0
Migration of context satellites
The context satellites were often used in the information marts. Therefore, we tried to limit as much as possible the impact by automatically migrating everything for you.
For each context satellite, the migration process will detect all the different sources present in the column “src” and generate one effectivity satellite per source.
Afterward, it will drop the context satellite table and replace it by a view of the same name. The view is a UNION of all the effectivity satellites of the entity.
This way, you shouldn’t have any manual migration to do and can continue to use the context view in your information marts
The view of the context satellite generated during the migration process will not be generated or updated afterward. This means that if you create a new effectivity satellite (for a new source, for instance), it will not be included in the view.
For those new effectivity satellite, use them directly in your information marts.
An effectivity satellite will only be created if there is at least one mapping set as “Full load” in the source system for that entity.
You might have some issues in your information marts if you filter the data on a context satellite loaded only by delta loads, which is not correct in a modeling perspective.
Example
In the following context satellite on the hub employee (dv.sh_employee_ctx), we have data coming from 2 different source systems.
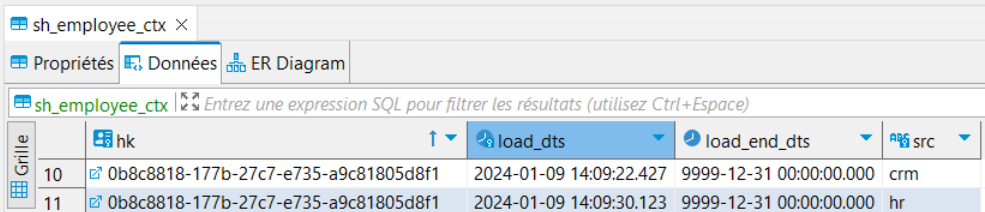
The migration process will detect the 2 different sources and create one effectivity satellite for each source system:
context satellite in v2.1
Effectivity satellites in v3.0
Pit tables
The name of the pit table changed
pt[h/l]_[parent]_[snapshot name] → [h/l]_pit_[parent]_[snapshot name]
The business key column in the pit table of the hub has changed.
[hub]_bk → bk_bk
If you used pit tables in your information marts, you will need to adapt them.
For the name, you can do a find/replace based on a regular expression to replace it everywhere:
search: bv.pt([hl]+)_
replace: bv.$1_pit_
Snapshot tables
Historically, beVault stored all the snapshot dates in one single table, ref.snapshot_dates. The Data Vault 2.0 standard states that the snapshot dates should be found in control tables in the information mart schema. Therefore, as of version 3.0, each snapshot created in beVault will create a table in the im schema.
Migration of snapshot tables
To ease the upgrade from version 2.1 to version 3.0, we replaced the table ref.snapshot_dates with a view of the same name and structure. This view is a UNION of all the newly created snapshot tables. This way, you shouldn’t have any impact by this change.
The view ref.snpashot_dates won’t be updated after the migration. This means that you need to use the new snapshot tables for the new snapshots that you create in version 3.0
Satellite view changed
Each satellite comes with a view to calculate the end date of each record (load_end_dts) with a window function. Since it is based on an enrichment, those views have been moved to the business vault schema.
dv.vs[h/l]_[parent]_[satellite] → bv.v_s[h/l]_[parent]_[satellite]
The migration process already replaced all the information marts found in the Distribute module. So, normally, you shouldn’t be impacted by this change.
If you have external processes or information marts that use those view, you should do a find/replace to adapt your script to the new name.
search: dv.vs
replace: bv.v_s
Hard rules
The format to reference a column in a hard rule has changed to avoid conflicts with SQL reserved keywords. Where you just had to specify the column name in your hard rule, as of version 3.0, you need to put it into double brackets : {{ column_name }}
The migration process already replaced all existing hard rules.
Some specific cases might need a manual fix, such as when the column name is a SQL reserved keyword used in the same hard rule.
Example: date::date
Data quality
Like for the hard rules, the format to reference a column in a data quality test has changed to avoid conflicts with SQL reserved keywords. Where you just had to specify the alias in your data quality test, as of version 3.0, you need to put it into double brackets : {{ alias }}
The migration process already replaced all existing data quality controls.
Some specific cases might need a manual fix, such as when the column name is a SQL reserved keyword used in the same test.
Example: date::date > NOW()
Multi-active satellite
The Vendor Tool Certification Program (https://datavaultalliance.com/certified-software-tools/) does not contain a delta-driven multi-active satellite implementation. This means that for the multi-active satellite, no hash diff is calculated and that all the records will be inserted each load.
To prevent an undesirable and significant expansion in the database size, which could potentially lead to system failures or exponential costs, we decided to discontinue support for multi-active satellites in version 3.0.
From our experience at dFakto, multi-active satellites should be used in last resort and are often a problem of granularity. If you encounter a business case where a multi-active satellite could be used, here are some alternatives to model them:
Use a dependent child on a link. As explained, multi-active satellites are frequently used, where it could be instead a link with a dependent child. Make sure to analyze correctly the granularity of your concepts to avoid unwanted multi-active satellites.
Use a hub with a concatenated business key. You can put your discriminant value in the hub’s business key to avoid having multiple records for one entry.
Use a JSON or Array column in a standard satellite. This way, you can store the multiple values that you could have for a record (bank accounts, phone numbers, etc…)
State Machines
The state machines' name generated by beVault have changed their name.
Those changes will impact your custom state machine. It will require changing the ARN of the state machine in the parameter stateMachineArn of the worker ExecuteStateMachine.
Load staging
The state machines to load data from the staging into the raw vault have the following format:
2.1: [project]-[environment]-[staging table name]
3.0: [project]_[environment]_Load_Staging_[staging table name]
Load snapshots and data quality controls
The state machines to load the snapshot group and execute the data quality control have the following format:
2.1: [project]-[environment]-[snapshot name]
3.0: [project]_[environment]_Load_Snapshot_[snapshot name]