How to extract data from a database?
This guide explains how to extract data from a database using beVault's data extraction capabilities. beVault uses a combination of stores, workers, and state machines to orchestrate data extraction workflows.
High-Level Schema
The data extraction process follows this flow: Source Database (e.g., Odoo) → SQLBulkInsert Worker → beVault Database
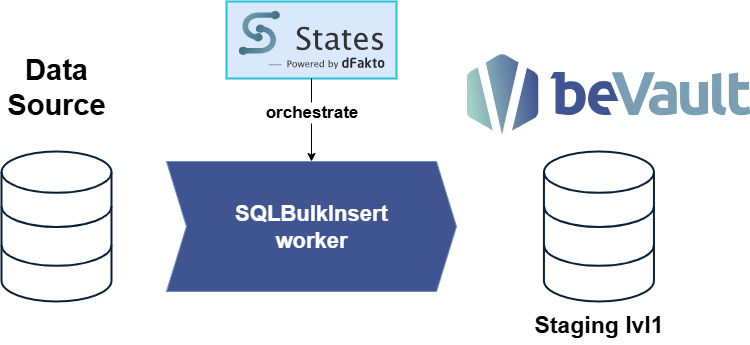
The SQLBulkInsert worker is the core component that handles data extraction and loading operations, moving data from source systems into beVault's staging area.
Simple example
The simple case demonstrates the most straightforward approach to data extraction in beVault. In this scenario, you'll extract data from a single table using a basic SQL query (like SELECT * FROM res_partner) and load it directly into beVault's staging area. This approach requires minimal configuration - just two database stores (source and destination) and a simple state machine with a single extraction step. It's ideal for getting started with beVault or when you need to extract data from individual tables without complex transformations or dependencies.
Configuration of stores
First, you need to configure the database stores that will be used for data extraction. Stores provide access to data sources and can be databases, directories, FTP servers, or other data repositories.
In this example, you will need two PostgreSQL stores, one for the Odoo’s database and one for the database generated by beVault.
Store configuration can be done in two ways depending on your beVault installation:
Option 1: JSON Configuration File
Create a stores.json file with the store configurations:
{
"Stores": {
"Stores": [
{
"Name": "system-odoo",
"Type": "postgresql",
"HealthCheck": true,
"Config": {
"ConnectionString": "Server=odoo_server;Port=5432;User Id=user;Password=password;Database=database"
}
}, {
"Name": "bevault-staging",
"Type": "postgresql",
"HealthCheck": true,
"Config": {
"ConnectionString": "Server=bevault-postgres;Port=5432;User Id=metavault;Password=password;Database=bevault_db"
}
}
]
}Note that the configuration must be adapted based on your infrastructure.
Option 2: Environment Variables
Alternatively, you can configure stores using environment variables:
DFAKTO_WORKERS_STORES__STORES__0__Name=system-odoo
DFAKTO_WORKERS_STORES__STORES__0__Type=postgresql
DFAKTO_WORKERS_STORES__STORES__0__HealthCheck=true
DFAKTO_WORKERS_STORES__STORES__0__Config__ConnectionString="Server=odoo_server;Port=5432;User Id=user;Password=password;Database=database"
DFAKTO_WORKERS_STORES__STORES__1__Name=bevault-staging
DFAKTO_WORKERS_STORES__STORES__1__Type=postgresql
DFAKTO_WORKERS_STORES__STORES__1__HealthCheck=true
DFAKTO_WORKERS_STORES__STORES__1__Config__ConnectionString="Server=bevault-postgres;Port=5432;User Id=metavault;Password=password;Database=bevault_db"Important: After modifying store configurations, you must restart the workers for the changes to take effect:
docker compose restart workersThis ensures that the workers reload the new store configurations and can establish connections to the updated data sources.
Example State Machine
For a simple data extraction, create a basic state machine in States that extracts all data from a table:
{
"StartAt": "extract-partners",
"TimeoutSeconds": 180,
"States": {
"extract-partners": {
"Type": "Task",
"Resource": "Production-SQLBulkInsert",
"TimeoutSeconds": 180,
"Parameters": {
"Source": {
"ConnectionName": "system-odoo",
"query": {
"query": "SELECT * FROM res_partner"
}
},
"Destination": {
"ConnectionName": "bevault-staging",
"TableName": "res_partner",
"SchemaName": "stg",
"TruncateFirst": true
}
},
"End": true
}
}
}You might need to change the prefix of the activity name based on the EnvironmentName you declared for the workers during the installation. If you have a doubt, you can check the available activities on the “Activities” page in States.
Advanced example
For more complex data extraction scenarios, you may need advanced SQL queries that go beyond simple SELECT * statements. These queries might include joins or filters. Additionally, you may want to version control your extraction queries to track changes, collaborate with team members, and maintain consistency across environments.
In such cases, beVault allows you to store your SQL queries in a Git repository and reference them through a FileStore. This approach provides several benefits:
Version Control: Track changes to your extraction queries over time
Collaboration: Multiple team members can contribute and review query changes
Environment Consistency: Use the same versioned queries across development, staging, and production
Complex Logic: Store sophisticated queries with joins and filters
Furthermore, you often need to extract data from multiple related tables in a single workflow. The advanced state machine example demonstrates how to process multiple data packages in parallel, significantly improving extraction performance.
Naming Conventions
For this advanced approach to work effectively, follow these naming conventions:
Staging Tables: Format as
[source]_[data package](e.g.,odoo_companies,odoo_contacts)SQL Scripts: Format as
[data package].sql(e.g.,companies.sql,contacts.sql)
This consistent naming allows the state machine to dynamically map each data package to its corresponding SQL script and staging table, enabling automated processing of multiple extractions with minimal configuration
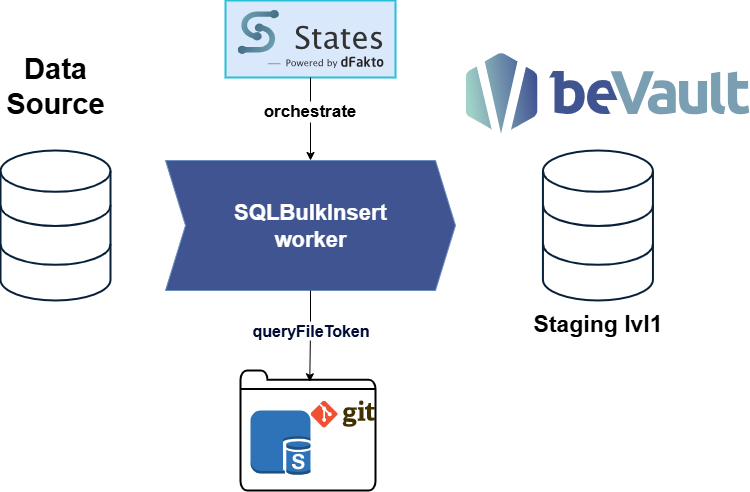
Configuration of Stores
For the advanced case, you need both database stores and a file store to access SQL scripts stored in a Git repository. Store configuration can be done in two ways depending on your beVault installation :
Option 1: JSON Configuration File
Create a stores.json file with the store configurations:
{
"Stores": {
"Stores": [
{
"Name": "system-odoo",
"Type": "postgresql",
"HealthCheck": true,
"Config": {
"ConnectionString": "Server=odoo_server;Port=5432;User Id=user;Password=password;Database=database"
}
}, {
"Name": "bevault-staging",
"Type": "postgresql",
"HealthCheck": true,
"Config": {
"ConnectionString": "Server=bevault-postgres;Port=5432;User Id=metavault;Password=password;Database=bevault_db"
}
},
{
"Name": "source-code",
"Type": "file",
"HealthCheck": true,
"Config": {
"BasePath": "/path/to/git/repository"
}
}
]
}Option 2: Environment Variables
Alternatively, you can configure stores using environment variables :
DFAKTO_WORKERS_STORES__STORES__0__Name=system-odoo
DFAKTO_WORKERS_STORES__STORES__0__Type=postgresql
DFAKTO_WORKERS_STORES__STORES__0__HealthCheck=true
DFAKTO_WORKERS_STORES__STORES__0__Config__ConnectionString="Server=odoo_server;Port=5432;User Id=user;Password=password;Database=database"
DFAKTO_WORKERS_STORES__STORES__1__Name=bevault-staging
DFAKTO_WORKERS_STORES__STORES__1__Type=postgresql
DFAKTO_WORKERS_STORES__STORES__1__HealthCheck=true
DFAKTO_WORKERS_STORES__STORES__1__Config__ConnectionString="Server=bevault-postgres;Port=5432;User Id=metavault;Password=password;Database=bevault_db"
# File store for SQL scripts
DFAKTO_WORKERS_STORES__STORES__2__Name=source-code
DFAKTO_WORKERS_STORES__STORES__2__Type=file
DFAKTO_WORKERS_STORES__STORES__2__HealthCheck=true
DFAKTO_WORKERS_STORES__STORES__2__Config__BasePath="/path/to/git/repository"Important: After modifying store configurations, you must restart the workers for the changes to take effect :
docker compose restart workersState Machine
The advanced state machine processes multiple data packages, each corresponding to a SQL script file:
{
"StartAt": "get-odoo-extracts",
"TimeoutSeconds": 1800,
"States": {
"get-odoo-extracts": {
"Result": {
"name": [
"companies",
"contacts",
"employees",
"invoice_lines",
"invoices"
]
},
"Type": "Pass",
"ResultPath": "$.data_packages",
"Next": "process-odoo-extract"
},
"process-odoo-extract": {
"Type": "Map",
"MaxConcurrency": 3,
"ItemsPath": "$.data_packages.name",
"ItemSelector": {
"data_package.$": "$$.Map.Item.Value"
},
"ResultPath": "$.extracted",
"ItemProcessor": {
"StartAt": "extract",
"States": {
"extract": {
"Resource": "Production-SQLBulkInsert",
"TimeoutSeconds": 180,
"Type": "Task",
"ResultPath": "$.taskResult",
"Parameters": {
"Source": {
"ConnectionName": "system-odoo",
"query": {
"queryFileToken.$": "States.Format('file://source-code/extracts/odoo/{}.sql', $.data_package)"
}
},
"Destination": {
"ConnectionName": "bevault-staging",
"TableName.$": "States.Format('odoo_{}', $.data_package)",
"SchemaName": "stg",
"TruncateFirst": true
}
},
"End": true
}
}
},
"End": true
}
}
}Data Package Organization
In the advanced case:
Data packages and staging tables must have the same name as the corresponding SQL script file
Each data package corresponds to a
.sqlfile in the Git repository (e.g.,companies.sql,contacts.sql)The state machine dynamically constructs file paths using the
States.Format()functionSQL scripts are loaded from the file store using the
queryFileTokenparameterStaging tables follow the naming convention
[source]_[data_package](e.g.,odoo_companies,odoo14_contacts)
This architecture provides a flexible and scalable approach to database extraction, supporting complex multi-table workflows with version-controlled SQL scripts and parallel processing capabilities.